
Recent studies evaluate developers’ privacy behaviors and show that developers generally see privacy as a burden and afterthought and are not familiar with basic privacy concepts. Less attention, however, is paid to understanding developers’ privacy needs and challenges in a systematic way.
In this project, we build a foundation for creating tools to improve developers' privacy awareness and expertise. We study and evaluate developers' privacy obstacles through user studies and analysis of questions and answers (Q&As) on developer forums and create and create a comprehensive dataset of privacy challenges for future research.
This project includes four specific outcomes: (1) a foundation for researchers and educators to understand and mitigate developers' privacy needs; (2) a tool-supported infrastructure to screen and classify developers based on their actual expertise; (3) models to extract, classify and summarize privacy Q&As from developer forums; and (4) a dataset of privacy Q&As labeled with their topics.


Most privacy solutions either focus on evaluating consistencies after development, or require a large amount of effort to identify and implement privacy controls. In addition, SE research strives to help developers write code through generating code fragments from natural language (NL) descriptions. Yet, these approaches do not consider privacy aspects. The code generation approaches rely on pretrained language models such as BERT or GPT and achieve high performance when they are pretrained on external resources and fine-tuned on smaller datasets.
In this project, we first develop approaches for developers and legal and policy experts to describe and reason about the privacy behaviors of an application prior to development, in terms of privacy stories and recommend and generate technical and policy solutions based on the privacy behaviors in a systematic and automated way through neural text generation approaches. Finally, we develop approaches, models and datasets to help generate privacy-related code snippets from NL descriptions (e.g., questions, privacy behaviors or stories) at the code level.
This project contains eight specific activities: (1) new scientific knowledge about applications' privacy behaviors pre-development; (2) common language between developers and legal experts to describe applications' privacy behaviors; (3) heuristics and models to detect privacy behaviors and generate privacy stories; (4) development of LLM models to translate privacy stories into technical and policy solutions; (5) development of LLM models to detect PRCS of Android and iOS applications; (6) two datasets of paired code snippets with privacy descriptions; (7) neural models to translate the descriptions to code snippets; (8) a privacy-intelligent recommender tool.
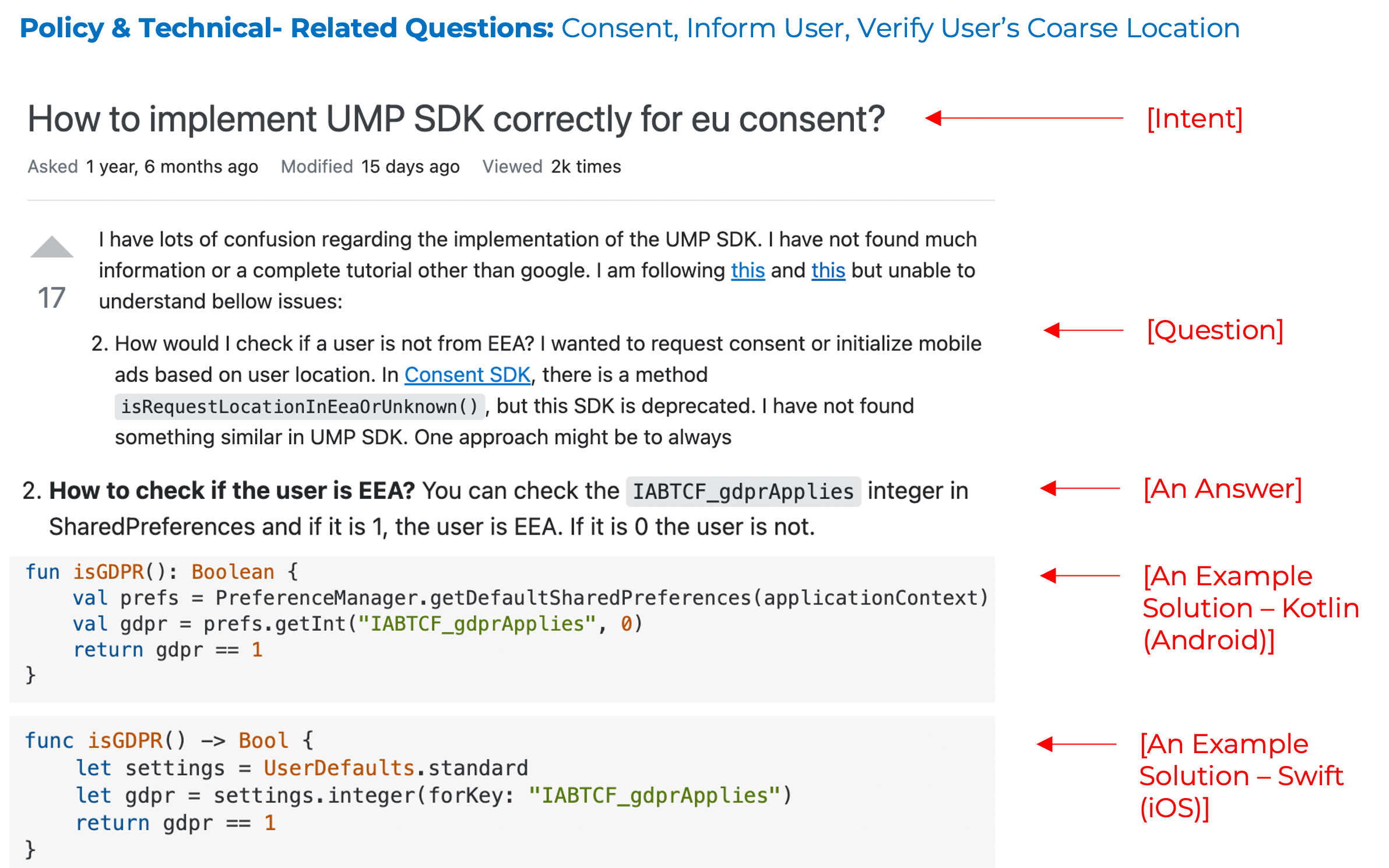
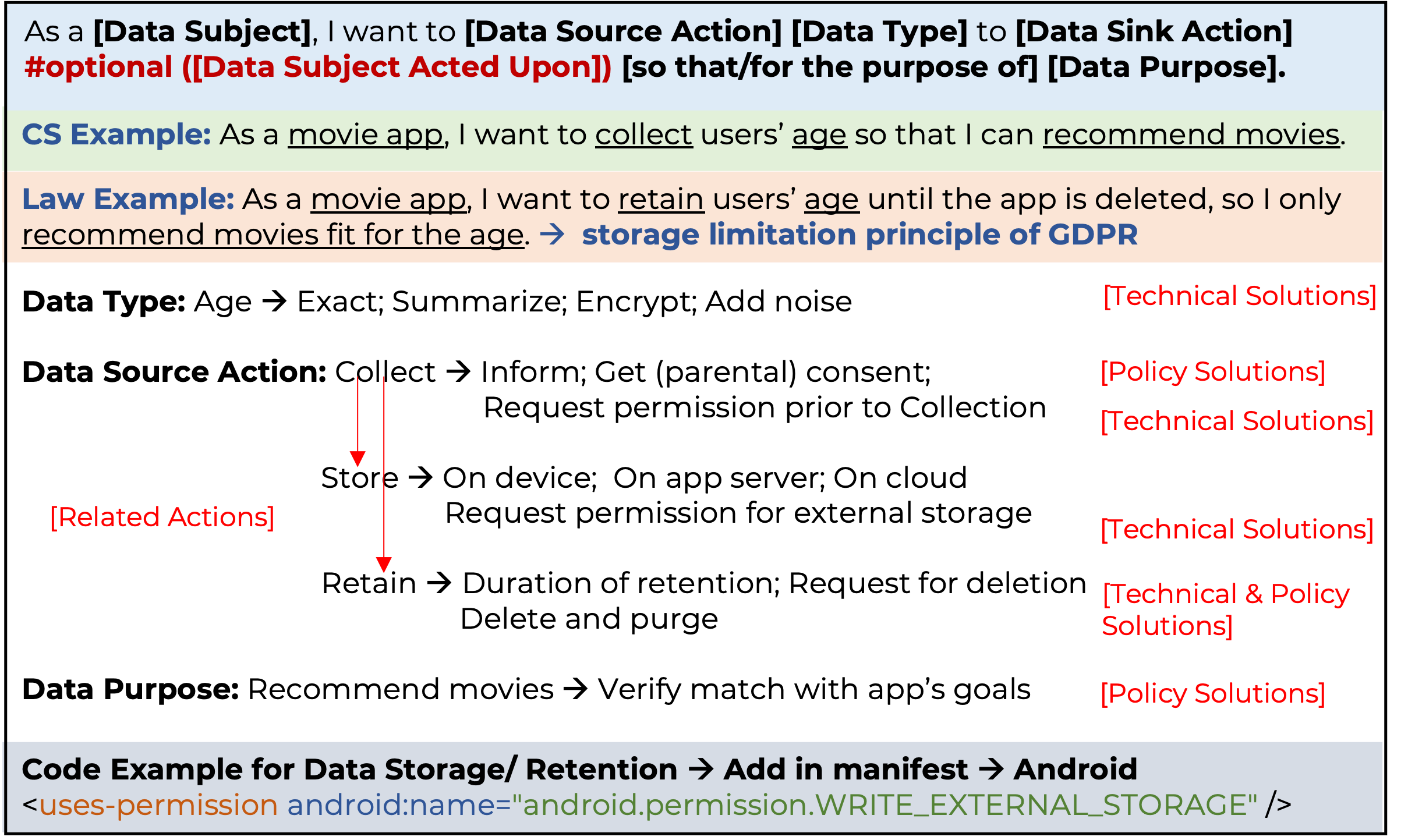
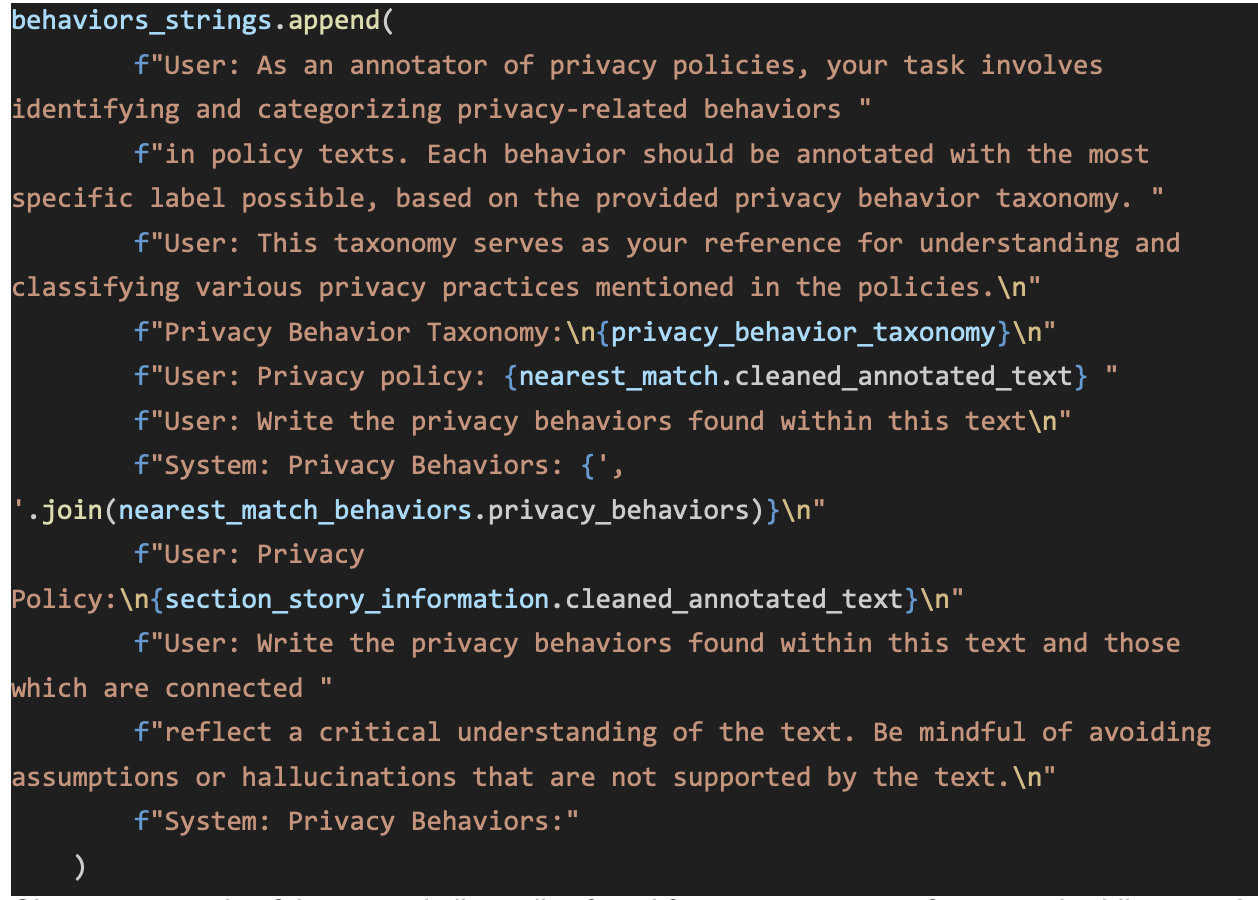
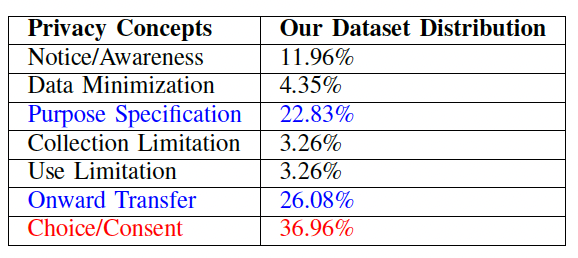
Privacy labels help developers communicate their application's privacy behaviors (i.e., how and why an application uses personal information) to users. But, studies show that developers face several challenges in creating them and the resultant labels are often inconsistent with their application's privacy behaviors.
The main goal PriGen is to help extract code segments, which process personal information (i.e., PRCS), and generate privacy descriptions (i.e., captions) through development of framework, models, datasets and a recommender system. This approach leverages and extends efforts in Neural Machine Translation where the source code is summarized into natural language comments or commit messages.
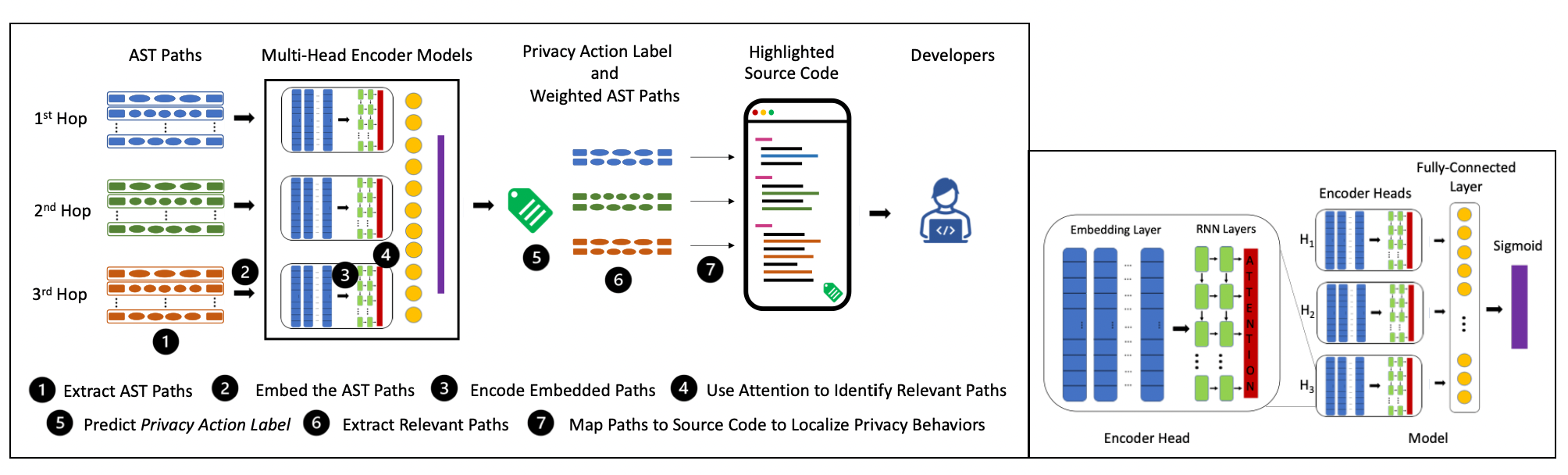
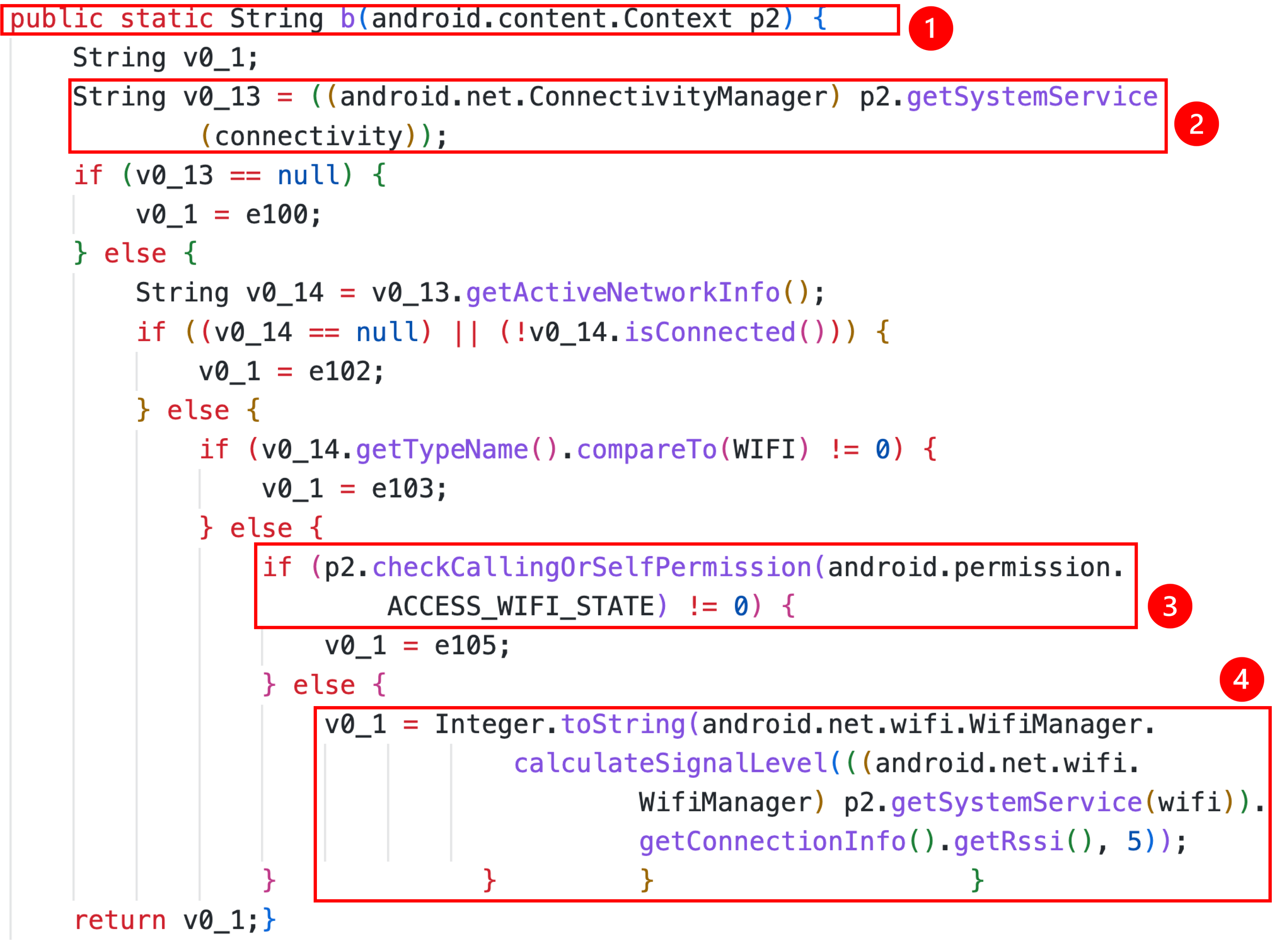
So far, we created a dataset of ~300,000 PRCS from ~80,000 APK files using our static analysis tool PDroid and predicted privacy captions by leveraging and training a deep learning model, Code2Seq. We extended this work by defining privacy behaviors as the combination of practices (i.e., how code uses personal information) and purposes (i.e., why?) and developed a Privacy Action Taxonomy (PAcT), which includes four practice (i.e., collection, processing, sharing and other) and four purposes (i.e., functionality, analytics, advertisement, and others) categories. By using PAcT, its heuristics, and our open-source annotation tool, Codr, we classified ~5,200 PRCS and built a multi-label, multi-class dataset with ~14,000 labels. we then created a novel methodology called fine-grained localization of privacy behaviors to locate individual statements in source code which encode privacy behaviors and predict their privacy labels. We design and develop an attention-based multi-head encoder model which creates individual representations of multiple methods and uses attention to identify relevant statements that implement privacy behaviors. These statements are then used to predict privacy labels for the application's source code and can help developers write privacy statements that can be used as notices. Our quantitative analysis shows that our approach can achieve high accuracy in identifying privacy labels, with the lowest accuracy of 91.41% and the highest of 98.45%.
Internet of Things (IoT) devices collects a massive amount of data from the users at a high rate than ever before. This increasing growth of the IoT poses a wide range of privacy and security threats to consumers. In a smart home environment, with a wide range of IoT devices, identifying potential privacy risks of deploying a new IoT device is still an open research scope.
The main objective of this project is to minimize the potential privacy risks as well as to increase users’ understanding of the privacy practices and risks of IoT devices so that they can make informed decisions about the devices and align their privacy preferences with the devices’ privacy behaviors. To achieve this goal, we develop a tool-supported privacy-aware framework for a smart home/work environment where users can communicate their privacy preferences with IoT devices through a privacy-enabled assistant tool, and be provided with a privacy risk report and guidelines to adjust their preferences so that the risk is minimized.
This project includes two specific tasks: (1) capturing and modeling users’ privacy preferences as well as IoT privacy practices and (2) Evaluating privacy risks for IoT devices.
Dozens of AI ethics initiatives and governance documents have emerged over the past few years, starting with the U.S. National Science and Technology Council’s ‘Preparing for the Future of AI’ and the E.U. Digital Charter in 2016. While AI ethics (initiatives) play an essential role in motivating morally acceptable professional behavior and prescribing fundamental duties and responsibilities of computer engineers and can, therefore, bring about fairer, safer, and more trustworthy AI applications, they also come with various shortcomings: One of the main concerns is that the proposed AI guiding principles are often too abstract, vague, flexible, or confusing and that they lack proper implementation guidance. Consequently, there is often a gap between theory (i.e., promise) and practice (i.e., performance), resulting in a lack of practical operationalization by the AI industry.
This project includes three tasks: In Task 1, we aim to refine AI ethics principles created by Dr. Wörsdörfer for developing ethical AI models and datasets based on the current proposed regulations, acts, and best practices. Our second (and third) tasks ensure AI developers and engineers (better) understand and (adequately) implement these guidelines. Task 2 involves conducting two studies (field study and survey study) with AI developers to better understand their challenges regarding AI ethics principles. In Task 3, we plan to provide companies with concrete and detailed guidelines for implementing the AI ethics principles identified in Task 1 in AI models and dataset.
Past Inactive Projects
Please check the Past Projects page for information on the previous projects of PERC_Lab.